Serverless computing is a trendy buzzword in the software industry. Serverless enables faster development by eliminating the need to manage Infrastructure, when creating a serverless application, the developer can fully focus on the application and let the cloud provider provision, scale and manage the infrastructure.
Serverless is a designation, it does not imply that the code does not run-on servers, because it does. Serverless means that the compute layer is abstracted from the underlying hardware and the architect/developer does not need to consider the aspects of running a server, such as network configurations or provisioning memory.
Serverless can scale rapidly and outside the constraints of hardware.Serverless applications are suitable for running code in the cloud without the need of provisioning servers. The pieces of code are usually rather small, following Microservices design patterns, however, there is no limit to how many pieces of code can be deployed into functions and it’s possible to build complex Event Driven / Message Driven applications using only serverless resources.
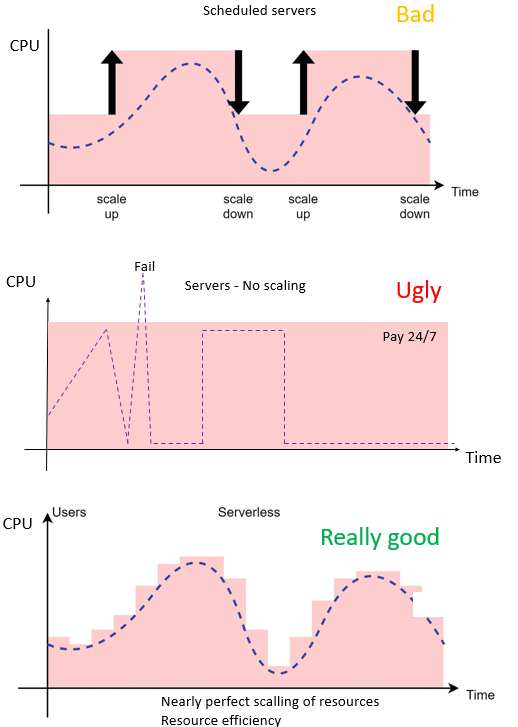
Serverless compute is billed by gigabyte/second, meaning that billing will depend on how much memory was used and how long the functions ran. On Azure, the consumption plan (pay-as-you-go) has no minimum cost, and the first 400.000 Gb/s and 1st million executions are free of charge. Functions have intrinsic scalability, in most projects where I’ve used serverless technology I did not need to scale up/scale out functions, I did, however, scale them down in some cases.
Serverless functions provisioned in consumption plans will scale down to zero when the services are not in usage. While this is very cost efficient, it also means that the next time the function runs, it needs to be reloaded from storage into memory. This characteristic is both a strength and a weakness. Functions may require a double-digit number of seconds to start and it’s often called “cold start”.
Because of cold starts, serverless functions might not be good choice for processes that involve user interaction, Functions are perfect for backend processes that either do not require user interaction or that interaction is asynchronous. One way to go around this is to have a minimum amount of provisioned “always-on” functions, this will result in a fixed cost equivalent to running a server, the advantage is that with functions you can still scale to 100 thousand instances very quickly without additional configuration and without a fixed cost associated to the capability to scale.Eventually, compute costs are the effect of using hardware that haslimited lifetime and energy costs. Serverless computing is often cheaper because there is less energy consumption and less hardware wear and tear. I believe that serverless is in most cases an environmentally friendly solution.
Message-driven architecture and event-driven architecture are both ways to design systems that process and act on asynchronous messages or events.
In message-driven architecture, messages are sent between components of a system and processed by each component. The sender and receiver of the message have a defined format and content of the message. The receiver processes the message and executes actions.
In event-driven architecture, events are broadcast to components, and each component can choose to act on the event. The components may have different roles, and the event itself carries the information that the component needs to process it.
Message driven and event driven are popular when implementing Serverless technologies, both are used to decouple the components of a system, allowing them to operate independently and handle changing loads. Event-driven architecture is more flexible than message-driven architecture, and is often used in systems that are highly distributed and need to scale horizontally.
Microservices is an architectural style that also often used in combination with Message-driven / Event-driven applications, where each service is responsible for a very specific task. A Message-driven and event-driven architecture can be used to implement the communication between microservices, each microservice can send and receive messages throuht a message queue or message bus, or subscribe to and publish events to an centralized event bus.
Together, microservices and message-driven or event-driven architecture can enable the creation of systems that are highly scalable, resilient and easy to evolve.
“If you chase two rabbits, you catch none – Confucius”.

· Triggers – Schedules or Events (new file, new message, new item in DB)
· Message queues – Assynchronous persistence between components
· FaaS – Functions-as-a-Service – Run and deploy code – Python, Javascript, C#, Java, Go, …
· Serverless Databases: Cosmos DB (Azure), DynamoDB (AWS), Firestore (Google)
When should serverless be used ?
For designing our compute strategy and defining compute resources, important criteria is are:
· Ease of configuration and maintenance
· Cost
· Elasticity
· Automation
The clear winner in all these categories are the serverless options, namely Functions as a Service (FaaS), however, it’s not always possible or recommended to use FaaS. I’ve created a decision tree based on my own experience. In this decision tree, we go for Azure Functions whenever we have a message driven or event driven short lived processes.
Keep in mind that a process can runs a million loops of 1 second (11.5 days) is not necessarily a long lived process, it could be redesigned into one million short lived processes and run in a few minutes instead.

Disadvantages
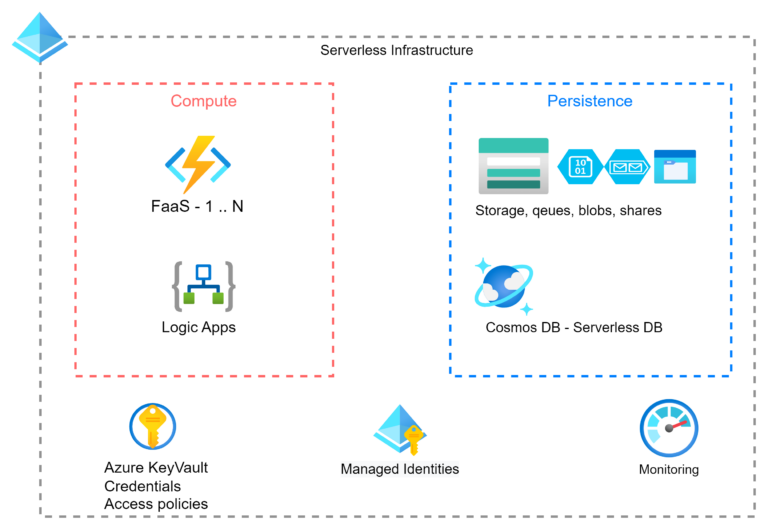
Example of Serverless architecture on Azure
Azure – Create your first function in the Azure portal
Google Cloud Platform – Create and deploy a Cloud Function
AWS – Run a Serverless “Hello, World!” with AWS Lambda
On the next articles on this serverless series, we will show how to create and deploy serverless functions on Azure and on Google Cloud Platform. We will also show how to build some more complex use cases using Azure cognitive services and also create and deploy a serverless React application.